Ich bin großer Fan von Reflection (Hallo, Johann 👋). Aber einige Sachen sind gar nicht soo offensichtlich hinzubekommen, etwa das Finden aller Sub-Klassen. Doch grämet euch nicht, es gibt Reflections:
Das ist tatsächlich nicht so trivial, aber der Reihe nach:
Wer danach googelt, findet erstaunlich (?) häufig den Ansatz, die URL auf endsWith(“.pdf”) zu prüfen 😳 Das sagt natürlich nichts darüber, ob das PDF auch dargestellt wird (oder ob es das richtige PDF ist), aber als erste Näherung habe ich das übernommen. Allerdings prüfe ich die URL etwas genauer, und vergleiche sie mit der URL, deren PDF-Ausgabe backendseitig bereits inhaltlich geprüft wird:
1
2
Stringexpected=getBaseUrl()+"item/[0-9]+/print"
url.matches(expected)
Kurz hatte ich dann überlegt, auf den Content Type zu prüfen, aber da kann natürlich alles drin stehen. Die o.g. Bedingungen stellt das ebenfalls nicht sicher.
Dann gibt es Ansätze, STRG+A/STRG+C zu nutzen (Beispiel), um den Inhalt des PDF zu verifizieren – funktioniert nicht mit jedem OS/Browser.
Dann, ebenfalls häufig genannt: PDFBox. Finde ich gut, so kommt man an den Inhalt des PDFs und kann sicherstellen, dass es das richtige PDF ist:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
importorg.apache.commons.codec.binary.Base64
importorg.apache.pdfbox.pdmodel.PDDocument
importorg.apache.pdfbox.text.PDFTextStripper
// test if there's a PDF at this URI:
PDDocument pdf=getAsPDF(url)
noExceptionThrown()
pdf!=null
// and if the PDF seems to be valid:
Stringtext=extractTextFromPDF(pdf)
text.contains("foo bar")
// ... mit:
PDDocument getAsPDF(StringtheUrl)throwsException{
// bonus points: The end point needs authentification :-)
Nachteil: Dass die URL [ein|das richtige] PDF ausliefert, sagt natürlich nichts darüber, dass das im Browser dargestellt wird 🙃
Also: Screenshot machen. Allerdings nicht die Selenium-Methode, denn aus Browser-Sicht ist die Seite “leer”, das PDF wird von einem Plugin gerendert. Die Lösung dazu: Robot.
ACHTUNG: Das geht nicht in einer “headless”-Umgebung, wie man sie bsplw. auf vielen CI-Servern findet:
java.awt.AWTException: headless environment
Mit einem waitFor, bis das PDF tatsächlich gerendert wurde (denn das ist ungleich “die Seite wurde geladen”):
Vorab: Ja, es gibt @RequestBody. Und es ist hässlich. Ich habe es nicht mal eingebaut. Aber ich musste es googlen und will das nicht noch mal tun müssen:
Googelt man “open file” etc., geht es meistens darum, eine Datei einzulesen. In meinem konkreten Fall wollte ich sie aber öffnen, also bsplw. ein PDF im Reader. Lösung:
Neulich™ hatte ich das Problem, dass ein UTF-8-enthaltender String falsch nach XML transformiert wurde. UTF-8 ist (? war es zumindest früher oft) so eine Sache in Java, man muss(te) an drölf Stellen das Encoding explizit setzen; dazu gehörten zB Stream, Writer/Reader, StringBuilder, etc pp. Das mag inzwischen anders sein, denn nach langem Debugging stellte sich raus, dass nur das File-Encoding in IntelliJ falsch gesetzt war – der Code funkionierte ohne Änderung, die Quelle des Strings war bereits fehlerhaft gespeichert. Irreführenderweise hatte der IntelliJ-Debugger den String die ganze Kette hindurch korrekt angezeigt. “Nimm IntelliJ” haben sie gesagt, “das funktioniert super” haben sie gesagt. m(
Wie dem auch sei: Da UTF-8 an der Stelle zwingend gefordert war, musste sichergestellt werden, dass kein Entwickler, aus welchen Gründen auch immer, ein anderes Encoding einschleust, bzw., wie in diesem Fall, UTF-8 durch falsch konfiguriertes Encoding kaputtspeichert. Ein Ansatz könnte sein, im Git-Repo UTF-8 zu erzwingen. Ein Ansatz dafür kann sein, das Encoding in einem Git-Hook zu prüfen. Anbieten tun sich pre-commit (der erste Hook, der greift; client-seitig; Beispiel [1] [2]) und pre-receive (der erste serverseitige Hook; Beispiel).
[Für Stash/Bitbucket Server scheint es auch Möglichkeiten zu geben; ein fertiges Plugin habe ich aber nicht gefunden.]
pre-commit hat den Vorteil, dass sich keine Commits aufstauen, bevor das Problem auffällt. Dafür müssen lokale Hooks aufwändig verteilt/aktiviert werden – bsplw. über separat eingecheckte Verzeichnisse, die gesymlinkt (aber was ist mit Windows? Was mit wirklichlokalen Hooks? Und was ist noch zu beachten?) oder kopiert werden. Für pre-receive gelten Vor- und Nachteile inversiert, außerdem benötigt man Zugriff auf den Server auf Dateisystemebene.
Lange Rede, kurzer Sinn: Aus Gründen haben wir uns für einen pre-commit entschieden. Das Skript muss dabei .git/hooks/pre-commit heißen. Ich hätte ein Verzeichnis pre-commit mit Skripten darin erwartet, aber das wirft einen
cannot spawn .git/hooks/pre-commit: No such file or directory
Und es war gar nicht so einfach, eine Datei überhaupt mit dem falschen Encoding abzuspeichern. Sublime und Notepad++ haben sich (stillschweigend, was Notepad++ angeht) geweigert. Schließlich habe ich es mit IntelliJ geschafft, was allerdings auch gewarnt hat. Keine Ahnung, wie das ursprüngliche Problem überhaupt zustande kam.
[Achtung: Das Skript kann nicht mit Binaries umgehen! Und das schließt bereits .woff ein. Offenbar ist es auch nicht trivial, Binaries zu erkennen; Internet nutzt dazu die Dateigröße oder auch Fileextensions. Ersteres scheint mir unzuverlässig, man denke an kleine Grafiken. Zweiteres ist sehr aufwändig…]
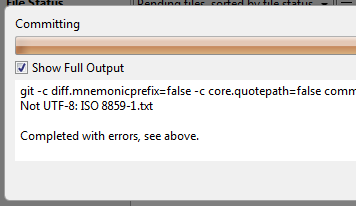
Beispielhafte Ausgabe (“ISO 8859-1.txt” heißt die Datei):
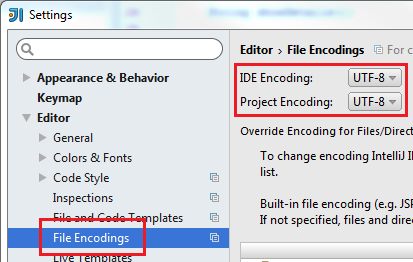
Und, der Vollständigkeit halber: Die Einstellung von Intellij:
btw: In Eclipse kann man Settings als Textfile exportieren und bsplw. in einem Repo ablegen – in IntelliJ scheint das nur als .jar exportierbar zu sein, bzw. über einen “IntelliJ Configuration Server” (WTF!?) verteilbar?