Nachdem despotify nicht mehr läuft, war es lange ruhig um die Idee. Bis ich vor einigen Tagen über Pi MusicBox gestolpert bin. Und, was soll ich sagen: Läuft wie ‘ne 1. Und:
hat dazu einen Webserver gleich mit an Board, der ein (mobiltaugliches) Interface (in iPhone-Optik) raushaut
zumindest auf den ersten Blick ist es absolut transparent, woher der Track kommt. Sprich: Man hat alle Quellen in einer Suche vereint
klingt in 320kbps über HDMI an meinem Yamaha absolut bombe! 🙂
Basiert auf Mopidy, was ich ebenfalls noch nicht kannte. Mopidy kann wohl auch Soundcloud, was ich im Pi-Interface (und auch im Config-File) nicht sehe.
Was mir fehlt, ist die Möglicheit, das Gerät aus dem Webinterface heraus runterzufahren. Und, gut zu wissen, der SSH-Zugang ist nicht pi/raspberry, sondern root/musicbox… Shutdown dann per “shutdown -h now”, wie gehabt
[UPDATE] Über USB-WLAN (der Stick zu 7,77 € auf Ebay oder 8,84 € auf Amazon) funktioniert das ziemlich out-of-the-box, allerdings musste ich in /etc/network/interfaces die Zeile auto wlan0 einkommentieren (Quelle). Den WLAN-Key muss man übrigens ohne Bindestriche oder Leerzeichen hinterlegen.
Inspiriert von Jan-Eike würde ich gern auch noch meinen Senf dazu abgeben: Was tun bei PRISM?
Naheliegend würde ich sagen:
Möglichst viel selbst hosten
Den Rest in Deutschland hosten
Den Rest möglichst dezentral hosten.
Im Detail heißt das zu 1. (wohlgemerkt alles auf Billig-Webspace bei Strato gehostet):
Ich nutze fever als Reader. Funktioniert ganz gut, allerdings lese ich nur im Browser. Die Apps für OS X, Windows Phone, mobil allgemein habe ich nie ausprobiert
shaarli für Bookmarks. Ist hässlich, funktioniert aber super
PS: Das kann man natürlich auch im eigenen Wohnzimmer hosten, etwa mit einem besseren NAS
PPS, in diesem Zusammenhang: Von PGP halte ich wenig. Wo soll ich meinen private key erstellen und speichern? Auf einem korrumpierten OS??
Nicht so schön geschrieben wie sonst, aber mit Hinweis auf wichtigen Punkt: “Wer meine Daten lesen kann, kann sie auch schreiben – siehe Bundestrojaner” sagt sinngemäß Sascha Lobo
Älter aber relevant:
Datenüberwachung nur gegen Terroristen und Kapitalverbrecher? Schon 2010 spionierten die USA private (!) Facebook-Nachrichten von zukünftigen Au-Pair-Mädchen aus. So viel auch zum Daten-Dementi von Mark Zuckerberg…
Internet kein rechtsfreier Raum? Datenüberwachung nur nach Gerichtsbeschluss? US Supreme Court entscheidet: Wer sich auf seine “Miranda-Rechte” (das Recht zu schweigen, das Recht auf einen Anwalt, …) beruft, bevor diese ihm vorgelesen wurden (und, wohlgemerkt, die müssen im eigentlich sofort vorgelesen werden!), der darf als schuldig gelten. Weil: Warum sons würde er schweigen, klar.
Selbst, wenn man den USA zubilligen würde, ihre eigenen (und nur die) Bürger zu bespitzeln, wird auch das nach hinten losgehen.
Microsoft treibt’s doller: M$ liest URLs aus Skype-Chats nicht nur mit, sondern besucht diese auch – sogar die mit Login-Parametern oder Session-IDs. Auf Nachfrage wurde diese Praxis dementiert – und stillschweigend “abgeschaltet” (vermutlich verwenden sie jetzt Proxys oder so). Nach der Miranda-Logik von oben werte ich das als Schuldeingeständnis.
Blackberry treibt’s noch doller: Die speichern nicht nur Login-Daten des Mail-Accounts, sondern loggen sich sogar dort ein! [Danke, Joost]
Menu “File” -> User Preferences -> Addons -> Install from File… -> ZIP auswählen
Das Addon sollte dann vorgefiltert in der Liste erscheinen; man muss es noch mit der Checkbox ganz rechts aktivieren
Blender evt. neustarten; die neue Exportfunktion sollte sich unter Menu “File” -> Export -> “Export XAML Scene (.xaml)” finden. Achtung: Ein Export dauert relativ lange. UPDATE: Dauert nur so lange, wenn das Modell scheiße ist aus sehr vielen Polygonen besteht.
Gerade beschäftige ich mich mit Bilderkennung, genauer gesagt mit dem Erkennen von Personen und deren Eigenschaften (“Features”). Dabei ist wenig vorgegeben, aber man landet recht schnell bei zwei Kandidaten, je nach Anwendungsfall:
Bei der Kinect für Bewegungs- (Gesten-, …), Tiefen- und Gesichtserkennung
Bei OpenCV für “Feature Detection” im eigentlichen Sinne, also weniger “wo ist das Gesicht” oder “wie steht der Arm”, als “trägt das Gesicht eine Brille” oder “wie viele Finger zeigt die Hand”
Zwar bringt die Kinect ebenfalls die Erkennung bestimmter Features mit, OpenCV funktioniert nur halt allgemeiner. In erster Annährung habe ich mich trotzdem auf die Kinect konzentriert, damit geht insbesondere im Gesicht schon recht viel (und ich muss nur eine neue Technologie zur Zeit lernen):
Knifflig wird es, wenn man mehr als “nur” das Gesicht erkennen will – beispielsweise den Kopf als Ganzes. Oder die Frisur. Oder auch nur die Haarfarbe. Darum soll es im Folgenden gehen – wobei ich explizit nicht behaupte, dass das nicht anders einfacher geht! Hier nur meine Versuche und Erkenntnisse, vielleicht helfen sie ja wem.
// bounds of rect around head (including some padding and dynamic height):
xx=face.Left-20;
yy=(int)(face.Top-face.Height/1.5);
ww=face.Width+40;
hh=face.Bottom-yy;
, in dem man auf Basis der Tiefeninformationen Kopf von Wand unterscheidet. Vorteil wäre, dass zB blonde Haare nicht für Wand gehalten werden. Aber #1: Man hat zwar die Tiefendaten des Kinectsensors, aber diese kann man nicht “mal eben” über die RGB-Daten der Kamera legen. Das liegt (neben den unterschiedlichen Auflösungen der beiden Sensoren) am sogenannten “Schatten”, der dadurch entsteht, dass Tiefensensor und Kamera eben zwei diskrete Sensoren sind, die nebeneinander liegen. Der Tiefensensor guckt also “von der Seite” auf die Szene der Kamera. Im folgenden Bild durch den schwarzen, nunja, Schatten visualisiert:
Dessen ist Microsoft sich bewusst, und stellt Funktionen wie MapDepthFrameToColorFrame() bereit – mit mäßigem Erfolg:
Man beachte: Der Umriss ist schon irgendwie OK (aber in x-Richtung gestreckt?), aber vor allem rechts auf dem Bild sieht man eine Lücke. Man kann diesen Schatten zwar kompensieren, das ist aber nicht unbedingt trivial, außerdem gibt es noch das Aber #2, und das sieht man hier nicht so direkt: Der Tiefensensor hat Probleme mit Haaren. Hochstehende Frisuren werden “abgeschnitten”.
Deshalb zweiter Ansatz auf Basis von Farbwerten. Das scheint durchaus erfolgsversprechender, wie ein Paper der Universität von Maryland (lokale Kopie) nahelegt, die machen genau das (Algorithmus ab 2.1; Ergebnis dann auf Seite 5). Im ersten Schritt messen sie die Durchschnittsfarbe der Haut, und zwar unter beiden Augen und über der Nase (siehe Seite 4). Im obigen Screenshot sieht man das schon, dieser bräunliche Kasten links ist meine durchschnittliche Hautfarbe:
Ergänzend (und analog) bilde ich die Durchschnittsfarbe der Wand links und rechts von dem Kasten um meinen Kopf. Dann kann ich alle Pixel des Kopfkastens durchiterieren, und Wand, Haut und Rest unterschieden:
Ich spare mir an dieser Stelle den Code der Erkennung, man muss recht viel feintunen:
Beispielsweise wird heller Schein auf der Haut als Wand erkannt, weshalb ich beide Hälften des gesichtes separat behandel – dadurch kann ich davon ausgehen, dass wenn der Kopf (die Wand) begonnen hat, keine Wand- (Kopf-) Pixel mehr kommen.
Ich gehe aber erst nach zwei entsprechend erkannten Pixeln davon aus, Kopf (Wand) gefunden zu haben, um toleranter gegen Fehlmessungen zu sein…
…außerdem verwende ich unterschiedliche Thresholds für jede Hälfte, da das Licht an meinem Schreibtisch von der linken Seite kommt – rechts ist dadurch dunkler.
Ergänzend addiere ich einen Offset (“lightningOffsetLeft” im obigen Code; kann auch negativ sein), um diesen Lichteinfall zu kompensieren
Das geht dann schon ganz gut:
Und man könnte sich denken: Wow, sogar Bart und Brille werden “erkannt”. Nicht so schnell, so sieht jeder aus, auch Leute ohne Bart und Brille.
Mir geht es hier nur um Frisur und (primär) Haarfarbe, deshalb ignoriere ich die Pixel im Gesicht: Dafür lege ich um die Nasenspitze eine Ellipse, und ignoriere alle Pixel innerhalb dieser Ellipse:
Außerdem ignoriere ich bis auf Weiteres alle Pixel unterhalb der Nase, um mir Probleme mit der vergleichsweise schattigen, also dunkleren, Region unter dem Kinn zu ersparen. Das Ergebnis:
ist nicht soo schlecht! Aber (es gibt immer ein aber): Man bekommt tatsächlich Probleme, wenn Haut, Haar (und hier die Wand) ähnliche Farben haben (auch hier ignoriere ich alle Pixel unterhalb der Nase!):
(Das Gesicht habe ich nachträglich verfälscht. Danke an M. für’s Modellsitzen!)
Ideen, das zu vermeiden, wären zum Beispiel die Einbeziehung von Kantenerkennung, um “Ende” der Wand und “Beginn” der Haut zu erkennen… oder gibt es weitere Vorschläge? Bis auf Weiteres soll es das aber erstmal gewesen sein. HTH!
UPDATE
PS, hier noch ein paar Libraries, die nützlich sein könnten (ungetestet):
headtrackr, “Javascript library for headtracking via webcam and WebRTC/getUserMedia”
FaceTracker, “Real time deformable face tracking in C++ with OpenCV 2.”
ofxFaceTracker, “ASM face tracking addon based on Jason Saragih’s FaceTracker.”
Offiziell geht es um Autonome Waffensysteme – dass sie entstehen werden, was sie bedeuten, warum High-Tech-Länder anfälliger gegen sie sind. Aber ich würde dabei auch PRISM und die Datensammelwut von Google (Klarnamenzwang!) und FB im Hinterkopf behalten. Sehenswert!
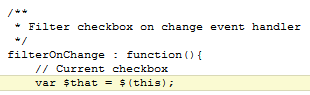
Kennt ihr das? Ihr googelt die Lösung eines Problems, findet genau eure Frage in einem Forum, mit der einen Antwort: “Hat sich erledigt, ich habe die Lösung”? Ohne zu verraten, wie diese lautet?
So auch hier. Witziges Detail dabei: Der User heißt “CompletelyUseless”.
^^