Seit Dezember 2012 habe ich ein Konto bei der ING DiBa. Brav habe ich die Kontoauszüge der letzten 12 Monate gescannt und überall meine Daten geändert. Überall? Nicht ganz. Denn bei Ebay ist das leider nicht so einfach.
Oh, es ist einfach, das Konto zu ändern, von dem Ebay abbucht. Das findet sich prominent unter Mitgliedskonto->Verkäuferkonto.
Es gibt aber noch ein weiteres Konto. Klar, jeder normale Mensch hat ja zwei verschiedene Konten für Ebay. Nicht. Das zweite Konto findet sich unter, Achtung: Mitgliedskonto->Einstellungen->”Zahlungseinstellungen für Käufer”->Einblenden->”Verwenden Sie Überweisung”->Bearbeiten.
Warum das Verkäuferkonto nicht das Konto ist, auf das ein Verkäufer sein Geld bekommt, und was ich mit den neun Leuten mache, die mir gestern und heute Geld überweisen wollten und mir jetzt vermutlich und zurecht eine schlechte(re) Bewertung geben, darauf bin ich mal gespannt. Antwort von Ebay steht aus.
Einer der Nachteile von Fever gegenüber dem Google Reader ist, dass es sich erstmal nicht von haus aus selbst aktualisiert. Was auf der Hand liegt; dazu bedarf es zB eines Cronjobs. Die Möglichkeiten dazu bringt Fever mit; ein Aufruf von
http://myfeverdomain.com/?refresh
bzw. über die Kommandozeile:
1
curl-L-shttp://myfeverdomain.com/?refresh
tut genau das. Dabei werden die eigenen Abos nicht angezeigt, man könnte diesen Aufruf also auslagern. Ideal, wenn man (wie ich) kein Hostingpaket mit Cronjobs hat.
Also: OS X basiert auf Unix. Unix kann Cron. Man könnte jetzt den Job manuell anlegen, das hat hier aber aus irgendeinem Grund nicht geklappt, und leichter geht es sowieso mit Cronnix: Neu -> Einfach -> Bei “Minute” “*/15”, bei allen anderen “*” eintragen, unter “Kommando” den o.g. Kommandozeilenbefehl hinterlegen -> fertig. Wann immer mein Rechner läuft, wird mein Reader alle 15 Minuten aktualisiert. Für alle anderen Clients gibt’s ja immer noch den entsprechenden Button in der Fever-Oberfläche.
Am 13.3. hat Google angekündigt, den Reader einzustellen. Heise spricht von “zerstörtem Vertrauen“, woraufhin der ein oder andere Kommentar Naivität und/oder Weinerlichkeit unterstellt. Ich sehe das aber ganz genauso und möchte erklären:
Ich konsumiere im Netz, grob gesagt, drei Arten von Inhalten:
Bestimmte Informationen, die ich (mangels brauchbarer Alternative über Googles Suchmaschine) ungezielt suche, beispielsweise Lösungen zu Coding-Problemen.
Unbestimmte Informationen zu sehr bestimmten Themengebieten:
Zu einigen Themengebieten gibt es bereits aggregierende Seiten: Spon oder Tagesschau.de für News, Facebook oder Twitter für’s Social Web, etc
Zu allen anderen Gebieten nutze nutzte ich den Reader: Tech, Comics, Design, etc
Aus meiner Sicht hat Google am 13.3. angekündigt, mir den Zugang zu 1/3 meiner Netzinhalte zu kappen. Mit einer fadenscheinigen Begründung, wenn man sie denn überhaupt so nennen kann. Im Wesentlichen “weil es geht”.
Ich persönlich mag noch gar nicht abschätzen, was diese Entscheidung letztendlich bedeutet. Ich denke, auch bei Google wird man dies nicht können. Die Petition auf change.org verzeichnet 120.000 Unterschriften – in den ersten drei Tagen! Ich habe auch unterschrieben, aber halte es mit heise: Google kann mir zukünftig den Buckel runter rutschen. Die Nachricht vom Tod des Reader hat es bis in’s Fahrgastfernsehen des HVV gebracht, was mir sagt, dass Google entweder absolut unterschätzt hat, welche Bedeutung der Reader hatte – oder es war Google scheißegal. Beides untergräbt eben Vertrauen.
Es ist allerdings fast befreiend zu sehen, was in den letzten Tagen an Alternativen alleine zum Reader diskutiert wurde und wird: Feedly (basiert auf einem Browserplugin und ist mir zu “aufbereitet”), The Old Reader (schon vielversprechender, aber hoffnungslos überfordert mit der Masse an Umsteigern), fever (kostenpflichtig und selbstgehostet, trotzdem mein aktueller Favorit), …
Darüber hinaus sind mir einge Alternativen für Googles Kalender über den Weg gelaufen, allen voran sei das entsprechende Modul von ownCloud genannt. Es entstehen wieder Diskussionen über Alternativen zu GMail. Microsofts Online-Office ist eh eine Klasse besser als die Google Docs (schon, weil sie näher am “Original” sind). Mein Google+ Account habe ich schon vor Monaten gekündigt, es könnte auch schon in den Bereich eines Jahres oder mehr gehen. Die ersten wechseln von Chrome zurück zu Firefox. Usw usf.
Apropos Firefox: So eine Spannung habe ich zum letzten mal erlebt, als der Firefox die kritische Masse überschritten hat. Als die Leute gemerkt haben, dass sie nicht den Internet Explorer nutzen müssen. Das hat eine Entwicklung eingeleitet, die Microsoft doch ziemlich unter Druck gesetzt hat.
FPDF ist ein gutes Tool, um mit PHP recht einfach PDFs zu erstellen. Hier meine gesammelten Learnings nach der ersten Anwendung:
Eigene Fonts werden mit MakeFont() in für PHP verständliche Form gebracht (gibt’s auch als Online-Tool)
Die Einbindung eigener Fonts geschieht mittels AddFont(), wobei die “Font Family” der String ist, der in der mit MakeFont() erzeugten PHP-Datei $name heißt
Text, der mit Write() geschrieben wird, bricht die Seite nicht um
Text im Header bricht die Seite nicht um, Text im Footer bricht die Seite nicht um. Mir erschien es zuerst etwas uneinsichtig, wo ich den Content erzeuge – es gibt Header() und Footer(), aber kein Content() oder Body(). Der Grund: Header() und Footer() werden von AddPage() aufgerufen, und damit auch bei automatischem Page-Break. Sprich: Jedesmal; deshalb sind sie ausgelagert. Der Content dagegen wird nur ein mal hinzugefügt. In den Beispielen meistens von außen, aber es geht auch im Konstruktor.
Text bricht dann die Seite automatisch um, wenn er mit Cell() (man beachte Parameter “ln”) oder MultiCell() hinzugefügt wird
Text in Cell() bricht selbst nicht um, nur in MultiCell()
t scheint nicht zu funktionieren, n dagegen schon
Und schließlich, nicht direkt zu FPDF: Wenn es UTF8-Probleme mit Texten aus der Datenbank gibt, kann es daran liegen, dass der Text nicht UTF8-kodiert aus gelesen wird. Ein
Clicking the button adds the event to the phone calendar.
Mangels weiterer Anforderungen gehe ich mal von iPhone, Android, idealerweise Windows Phone als Zielplattform aus. Gehe ich also zur Wikipedia, und sehe mich ein wenig um:
vCal: “vCal is an open source calendar standard for Vision PIM”. Hm, klingt nicht so wie das, was ich suche. “vCal is not to be confused with the better known vCalendar format in that it is a completely different format” – Aha!
Gesagt, implementiert. Stellt sich aber heraus, dass die Kalender-App auf Android eine .ics-Datei nicht öffnen kann. Hm, kann nicht angehen! Hilfe der App geöffnet, “ics” gesucht, und Folgendes gefunden:
Termine aus iCalendar- oder CSV-Dateien importieren
Wenn Sie Termine aus iCalendar- oder CSV-Dateien importieren möchten, gehen Sie wie folgt vor:
1. Klicken Sie auf den Abwärtspfeil neben “Weitere Kalender”.
…
Nur: Wo ist der Button “Weitere Kalender”? Tja, nirgendwo! Die Hilfe der App ist nämlich die Onlinehilfe für www.google.com/calendar! Und da gibt’s den Button! Wie link ist das denn? Und ich suche den eine halbe Stunde lang!
Ungläubig surfe ich noch ein wenig rum, und finde einen entsprechenden Bug von sage und schreibe November 2008 (und immer noch aktiv!). Die Kommentare unter dem Bug werden zusehends schärfer, und das zurecht. Denn ich war auch weitere zwei Stunden später nicht in der Lage, ein dediziertes Kalenderformat zu identifizieren, das vom Android mit dem Kalender geöffnet wird (CSV ignoriere ich dabei, denn das wird im Zweifel mit dem Texteditor oder der Excel-App geöffnet).
Fairerweise muss ich sagen, das Windows Phones .ics-Dateien auch nicht öffnen können – aber zumindest behaupten sie nicht das Gegenteil 🙁
Naiv, wie ich nun einmal bin, war ich davon ausgegangen, dass das Windows Phone SDK einen gewissen Satz an Standard-Komponenten mitbringt. Zum Beispiel einen DatePicker (wie man ihn im Kalender findet) oder einen TimePicker (wie im Wecker). So Sachen halt.
Falsch gedacht.
Dafür muss man das “Windows Phone Toolkit” von http://phone.codeplex.com/ installieren (Achtung: Die URL http://silverlight.codeplex.com/ ist für Windows Phone veraltet!). Anmerkung: Obwohl das sehr nach Silverlight klingt, kann man es auch mit C#-Anwendungen nutzen. Für mich war das nicht selbstverständlich.
Offenbar gibt es verschiedene Möglichkeiten für die Installation; ich habe NuGet verwendet. Das zuerst installieren, (s)eine Solution öffnen, dann unter Tools -> Libarary Package Manager -> Package Manager Console -> “Install-Package WPtoolkit” eingeben. Das Toolkit wird dann nur für diese Solution installiert – was wichtig ist, denn:
Um das Toolkit auch tatsächlich nutzen zu können (obwohl man es ja gerade eben sogar für genau diese Solution installiert hat), muss man nicht nur den entsprechenden Namespace zum Beispiel seiner MainPage.xaml hinzufügen:
Sondern auch “eine Referenz” auf das im Namespace erwähnte “Assembly” hinzufügen. Und das ist schwierig, wenn man sich an die Anleitungen aus dem Internet hält (zum Beispiel diese oder diese). Denn erstens sieht man dort hin und wieder die veraltete URL http://silverlight.codeplex.com/, und zweitens findet man die Assembly-Datei Microsoft.Phone.Controls.Toolkit.dllnicht unter
bzw. analog. Halt nicht an globaler Stelle, sondern lokal im Projekt. Wenn man das weiß, fügt man diese ominöse Referenz wie folgt hinzu:
Solution Explorer -> References -> Rechtsklick, “Add Reference…” -> Browse… -> Microsoft.Phone.Controls.Toolkit.dll aus dem Projektverzeichnis suchen.
Nun sollte man bsplw den TimePicker mittels
1
<toolkit:TimePicker />
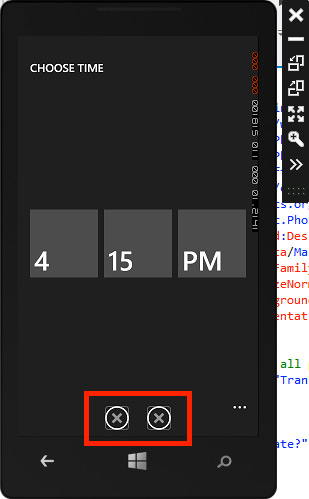
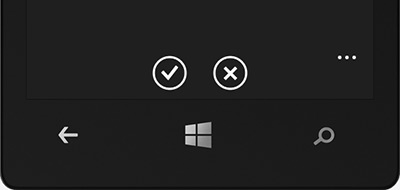
nutzen können. Aber: Im Emulator sieht man, dass die Icons für Bestätigen und Abbrechen fehlen:
Das Internet sagt hier, hier und hier, dass man einen Ordner “Toolkit.Content” mit den PNGs “ApplicationBar.Cancel.png” und “ApplicationBar.Check.png” anlegen soll. Also Rechtsklick auf Projekt im Solution Explorer -> Add -> New Folder (ist nur aktiv, wenn der Emulator nicht läuft) -> “Toolkit.Content”. Bei mir gab es daraufhin aber die Fehlermeldung “Cannot add a link to the folder Toolkit.Content. There is already a file of the same name in this folder.” Tatsächlich kann ich den Ordner im Windows Eplorer sehen – und die erwähnten PNGs ebenfalls 🙁 Doch wo sind sie im Solution Explorer, und warum sehe ich sie im Emulator nicht?
Die Antwort auf die erste Frage lautet: Weil das ein weiterer scheiß Bug ist! Visual Studio muss offenbar nach der Installation vom Toolkit neu gestartet werden, dann sieht man plötzlich auch den Ordner. Die Antwort auf Frage 2: Man muss einen Rechtsklick auf jedes PNG machen, und “Include In Project” auswählen. Dann geht’s:
Wenn man endlich den Windows Phone Emulator (in Parallels) starten darf, wird man von dieser Meldung empfangen:
The Windows Phone Emulator wasn’t able to create the virtual machine: Generic failure*
*Die Deutsche Version lautet genauso, nur der “Generic failure” ist ein “Allgemeiner Fehler”
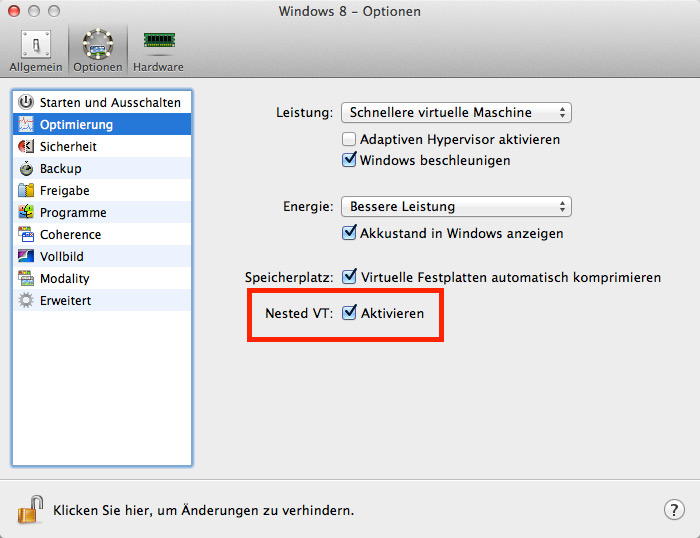
Der Grund ist im Wesentlichen, dass der Emulator eine virtuelle Machine ist – die man in einer virtuellen Maschine starten will. Das geht nicht zwingend; das Buzzword lautet “Nested Virtualization” (“Verschachtelte Virtualisierung”). Ein entsprechender Eintrag in der Parallels Knowledgebase (gefunden hier und hier) empfiehlt Folgendes:
UPDATE: wenn Parallels aktualisiert wurde, muss die VM evt neu installiert werden, damit die Option angezeigt wird. Das geht so weit, dass sogar das Intel Tool behauptet, dass die CPU das nicht unterstützt. Ein Blick in deren Datenbank schafft Klarheit
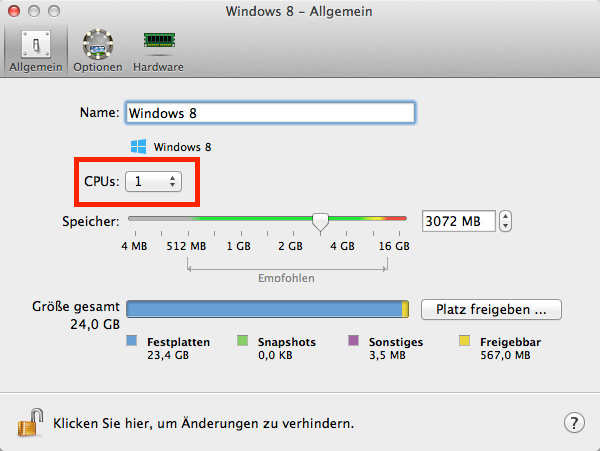
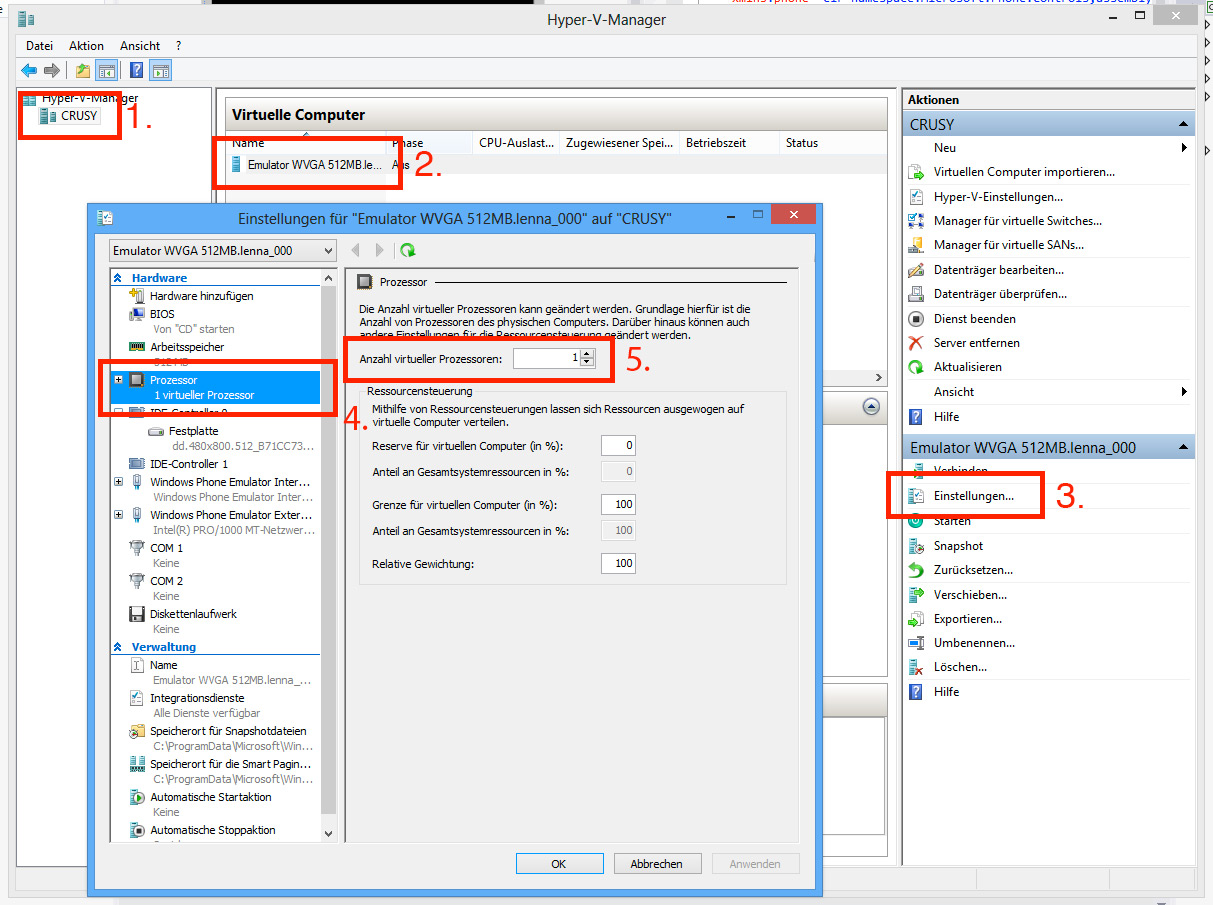
Windows’ “Hyper-V-Manager” starten, links den PC auswählen, unter “Virtuelle Computer” den Emulator auswählen (wenn er nicht erscheint: Visual Studio starten, Emulator starten), rechts auf “Einstellungen”, Prozessor, “Anzahl virtueller Prozessoren” (kann man nur ändern, wenn der Emulator aus ist): “1” einstellen:
Emulator starten 🙂
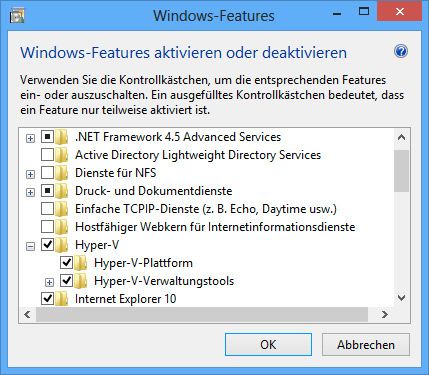
PS: Um herauszufinden, ob der Prozessor Nested VT unterstützt, kann man entweder entsprechende Tools (zum Beispiel das “Intel Processor Identification Utility”) nutzen, oder in die “Windows-Features” gehen: “Hyper-V” muss aktivierbar und aktiviert sein.
Windows 8 Pro frisch installiert, das Windows Phone SDK heruntergeladen, installiert und gestartet, quasi-leere Demo-App erstellt, “Emulator WVGA 512MB” gestartet – folgende Fehlermeldung (plus drölf weiteren) bekommen:
Error 1 The name “MainViewModel” does not exist in the namespace “clr-namespace:MyApp”.
Vermutung im Internet: Irgendwelche “Assemblies” seien nicht “korrekt” verlinkt. Aha. Kann sein, schließlich habe ich gar nichts verlinkt. Finde ich auch nicht nötig, um ein vorgegebenes Hello-World-Programm zu starten. Was für ein bekackter Bug soll das sein??
Lösung (Schritt 6, Achtung, extrem hässliche Seite): Das Projekt muss auf einer anderen Partitition als Visual Studio abgespeichert sein. WTF. Würde aber zu o.g. Vermutung passen – evt. kommt VS nicht mit relativen Pfaden klar?